Let me show you how you can migrate an Oracle Database into OCI. My source database is a CDB running on 12.1.0.2. I want to migrate to the same version using the Physical Online method which uses Data Guard.
This procedure can be used to migrate to:
- VM DB Systems
- Bare Metal DB Systems
- Exadata DB System (ExaCS)
If you want to migrate to Exadata Cloud at Customer and Exadata on-prem, you can use a lot from this post, but there are some differences which I will not cover.
Prerequisites
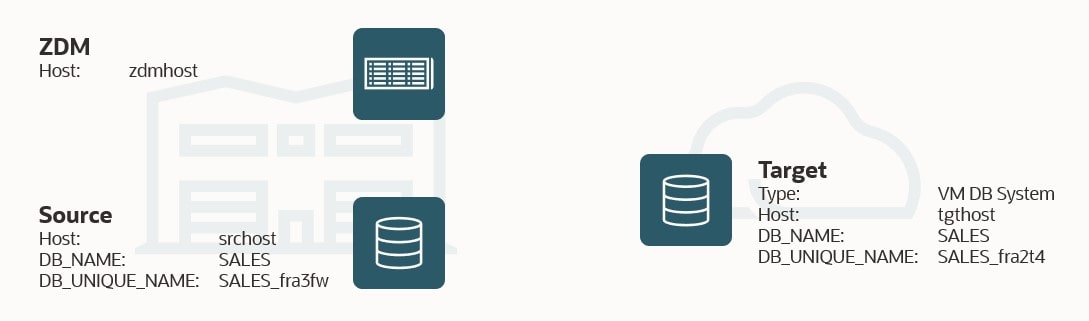
- I need a ZDM service host. It is called zdmhost and the user is called zdmuser.
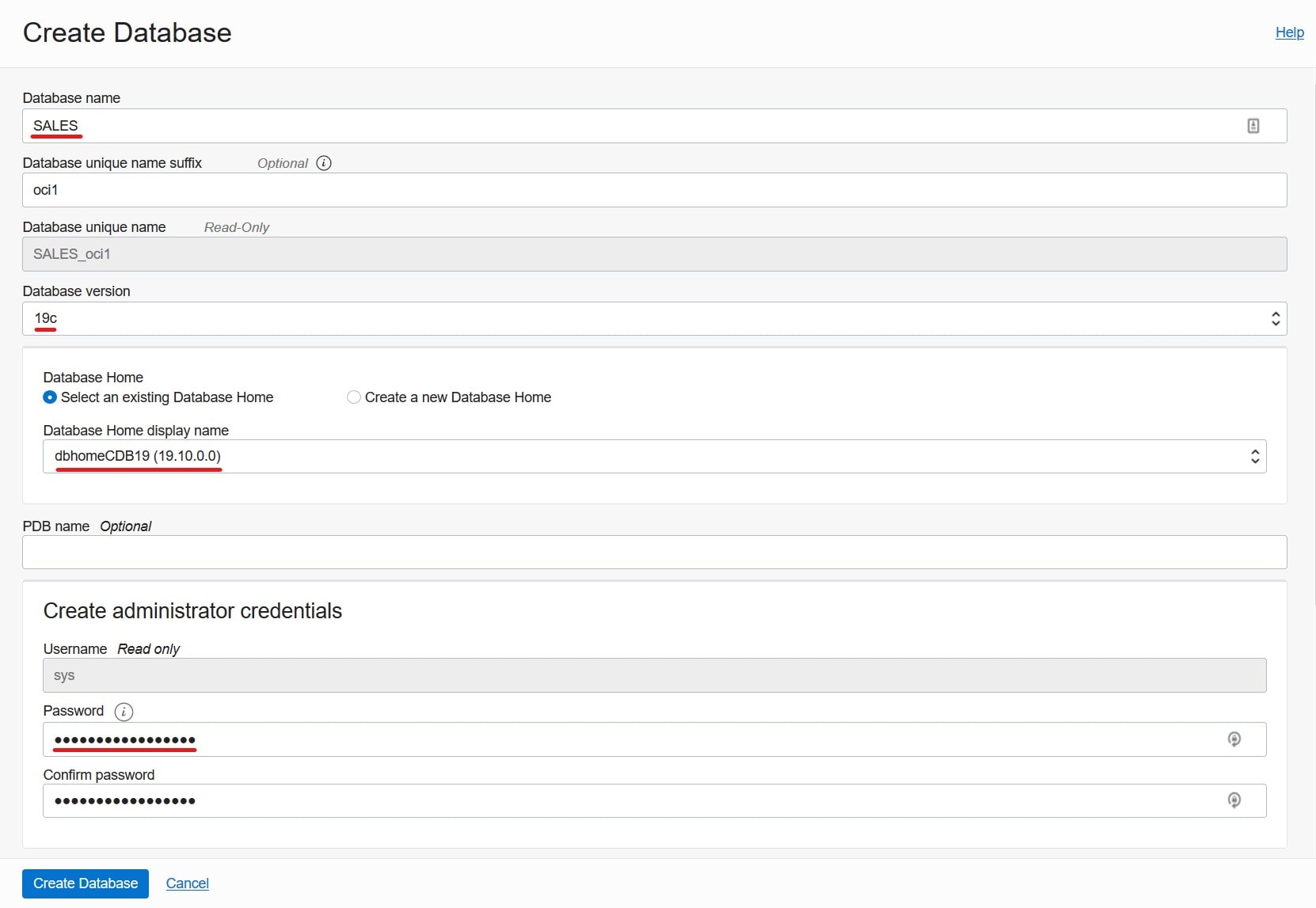
- My source database is a CDB called SALES (
DB_NAME), and the host is named srchost.
- I want to migrate to a VM DB System, and it is already created. I name it tgthost. I use the same name for the database, SALES. I must use ASM as storage management software.
Prepare Source
Ensure the database is in ARCHIVELOG mode:
select log_mode from v$database;
If database version is 12.2 or higher, a TDE keystore must be present – even if the database is not encrypted. A license is not needed to create a TDE keystore – not until data is getting encrypted. The keystore must be OPEN and the type is either AUTOLOGIN, LOCAL_AUTOLOGIN or PASSWORD. In a CDB, this applies to CDB$ROOT and all PDBs:
SELECT con_id, status, wallet_type FROM v$encryption_wallet;
If status is OPEN_NO_MASTER_KEY it means that no TDE master encryption key has been created and I will need to create one. Instructions are also in the documentation.
Ensure that the source host can resolve the network name of the target host. It is important to add two entries – one with the host name and one with the SCAN name (they should both point to the target host):
[root@srchost]$ echo -e "[ip address] tgthost" >> /etc/hosts
[root@srchost]$ echo -e "[ip address] tgthost-scan" >> /etc/hosts
Test connection over SQL*NET to the target:
[oracle@srchost]$ sqlplus system@tgthost-scan/[target-cdb-service-name]
Prepare Target
I need a target placeholder database. The placeholder target database is overwritten during migration, but it retains the overall configuration.
- VM DB System: When I create a new system, a database is automatically created. This database is my target placeholder database.
- Bare Metal and Exadata DB Systems: Create a new database on an existing system.
In any case:
DB_NAME must exactly match that of the source database – also in the same case.DB_UNIQUE_NAME must be different.- Use the same SYS password as the source database.
- Any database parameters for the target database, including SGA parameters, are maintained during the migration, and the migrated database runs with this same configuration.
- Do not enable automatic backup (until after the migration has completed).
- The architecture (single instance or RAC) of the target placeholder database determine the architecture of the OCI database. If I want my OCI database to be a RAC database, simply create the target placeholder database as a RAC database, and the end result will be a RAC database.
COMPATIBLE must match that of the source database.- The patch level of the target database must be equal to or higher than the source database. If they differ, ZDM will automatically execute
datapatch as part of the migration. Use $ORACLE_HOME/OPatch/opatch lsinventory.
- The source and target database must use the same time zone file version. If they don’t match, I must upgrade the time zone file in the source database. If I have a lot of data of type
TIMESTAMP WITH TIMEZONE and I can’t afford the downtime it takes to do the upgrade, then consider using the logical online method: select * from v$timezone_file;
There are a few other requirements listed in the document, but these are the most important ones.
Like the source host, the target host must be able to resolve the network name of its counterpart:
[root@tgthost]$ echo -e "[ip address] srchost" >> /etc/hosts
[root@tgthost]$ echo -e "[ip address] srchost-scan" >> /etc/hosts
And I test the connection:
[oracle@tgthost]$ sqlplus system@srchost-scan/[source-cdb-service-name]
Prepare ZDM
The ZDM service host must be able to resolve the host names of the source and target database host:
[root@zdmhost]$ echo "<source IP address> srchost" >> /etc/hosts
[root@zdmhost]$ echo "<target IP address> tgthost" >> /etc/hosts
I put my private SSH keys to the source and target database host into ~/.ssh directory. Ensure permissions are set properly:
[zdmuser@zdmhost]$ cp srchost_key_file ~/.ssh
[zdmuser@zdmhost]$ chmod 400 ~/.ssh/srchost_key_file
[zdmuser@zdmhost]$ cp tgthost_key_file ~/.ssh
[zdmuser@zdmhost]$ chmod 400 ~/.ssh/tgthost_key_file
Test the connection. I connect as opc, but you might have a different user. Read more about access to the database host in the documentation:
[zdmuser@zdmhost]$ ssh -i ~/.ssh/srchost_key_file opc@srchost date
[zdmuser@zdmhost]$ ssh -i ~/.ssh/tgthost_key_file opc@tgthost date
Prepare Response File
I will use a template response file as the basis for my response file:
[zdmuser@zdmhost]$ cp $ZDM_HOME/rhp/zdm/template/zdm_template.rsp ~/physical_online.rsp
[zdmuser@zdmhost]$ chmod 700 ~/physical_online.rsp
This is the response file that I end up with (see appendix B for an explanation):
TGT_DB_UNIQUE_NAME=SALES_fra2t4
MIGRATION_METHOD=ONLINE_PHYSICAL
DATA_TRANSFER_MEDIUM=OSS
PLATFORM_TYPE=VMDB
HOST=https://swiftobjectstorage.[region].oraclecloud.com/v1/[my-tenancy-object-storage-namespace]
OPC_CONTAINER=zdm-staging
SKIP_FALLBACK=TRUE
SHUTDOWN_SRC=TRUE
If your database is Oracle Database 11.2.0.4 be sure to set these response file parameters:
ZDM_RMAN_DIRECT_METHOD=ACTIVE_DUPLICATE
ZDM_USE_DG_BROKER=FALSE
Perform Evaluation
I am now ready to perform a migration evaluation. It is a dry run of the migration and performs various sanity checks. Nothing is changed during the evaluation:
[zdmuser@zdmhost]$ $ZDM_HOME/bin/zdmcli migrate database \
-rsp /home/zdmuser/physical_online.rsp \
-sourcenode srchost \
-sourcedb SALES_fra3fw \
-srcauth zdmauth \
-srcarg1 user:opc \
-srcarg2 identity_file:/home/zdmuser/.ssh/srchost_key_file \
-srcarg3 sudo_location:/usr/bin/sudo \
-targetnode tgthost \
-tgtauth zdmauth \
-tgtarg1 user:opc \
-tgtarg2 identity_file:/home/zdmuser/.ssh/tgthost_key_file \
-tgtarg3 sudo_location:/usr/bin/sudo \
-targethome /u01/app/oracle/product/12.1.0.2/dbhome_1 \
-backupuser "daniel.overby.hansen@oracle.com" \
-eval
A few comments:
sourcenode and targetnode are the host names of the source and target database host. Those names must be resolvable which I why I put them into /etc/hosts already.sourcedb is the DB_UNIQUE_NAME of the source database. My database is on ASM. If I didn’t use ASM I should use sourcesid instead and specify the database SID.srcarg1 is the name of the user that I connect as to the source database host. You might need to change that.srcarg2 and tgtarg2 is the location of the private key files to the source and target database host respectively. The private key file must be usable by the user that is specified in srcarg1 and tgtarg1 which in this case is opc.
I am prompted for the SYS password to the source database and also the password for the backupuser (which is my OCI user). For the latter, please note that this password is not my user password, however, it is an auth token. I also get a job ID:

The migration evaluation is then started, and I can use the job ID to monitor it:
[zdmuser@zdmhost]$ $ZDM_HOME/bin/zdmcli query job -jobid <job ID>
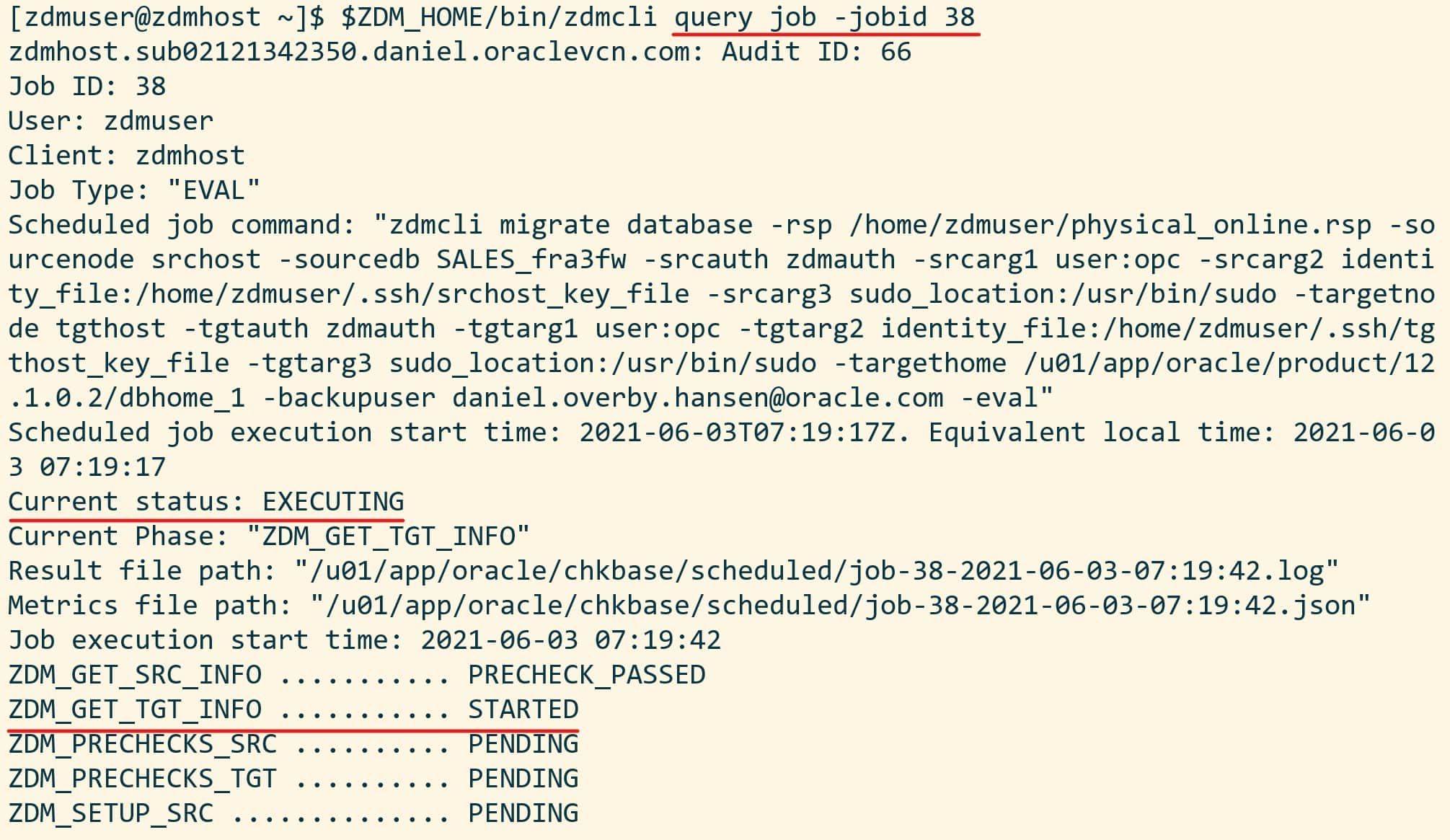
My colleague Sinan Petrus Toma showed how to loop:
[zdmuser@zdmhost]$ while :; do $ZDM_HOME/bin/zdmcli query job -jobid <job ID>; sleep 10; done
However, I prefer to get more details, so I tail the ZDM log file instead. This little one-liner finds the newest file and tails it:
[zdmuser@zdmhost]$ tail -n 50 -f "`ls -td /u01/app/oracle/chkbase/scheduled/*log | head -1`"
And I get this level of detail:
zdmhost: 2021-06-03T07:19:50.317Z : Starting zero downtime migrate operation ...
zdmhost: 2021-06-03T07:19:53.445Z : Executing phase ZDM_GET_SRC_INFO
zdmhost: 2021-06-03T07:19:53.446Z : Retrieving information from source node "srchost" ...
zdmhost: 2021-06-03T07:19:53.447Z : retrieving information about database "SALES_fra3fw" ...
zdmhost: 2021-06-03T07:20:02.743Z : Execution of phase ZDM_GET_SRC_INFO completed
zdmhost: 2021-06-03T07:20:02.826Z : Executing phase ZDM_GET_TGT_INFO
zdmhost: 2021-06-03T07:20:02.827Z : Retrieving information from target node "tgthost" ...
zdmhost: 2021-06-03T07:20:12.197Z : Determined value for parameter TGT_DATADG is '+DATA'
zdmhost: 2021-06-03T07:20:12.198Z : Determined value for parameter TGT_REDODG is '+RECO'
zdmhost: 2021-06-03T07:20:12.198Z : Determined value for parameter TGT_RECODG is '+RECO'
zdmhost: 2021-06-03T07:20:12.203Z : Execution of phase ZDM_GET_TGT_INFO completed
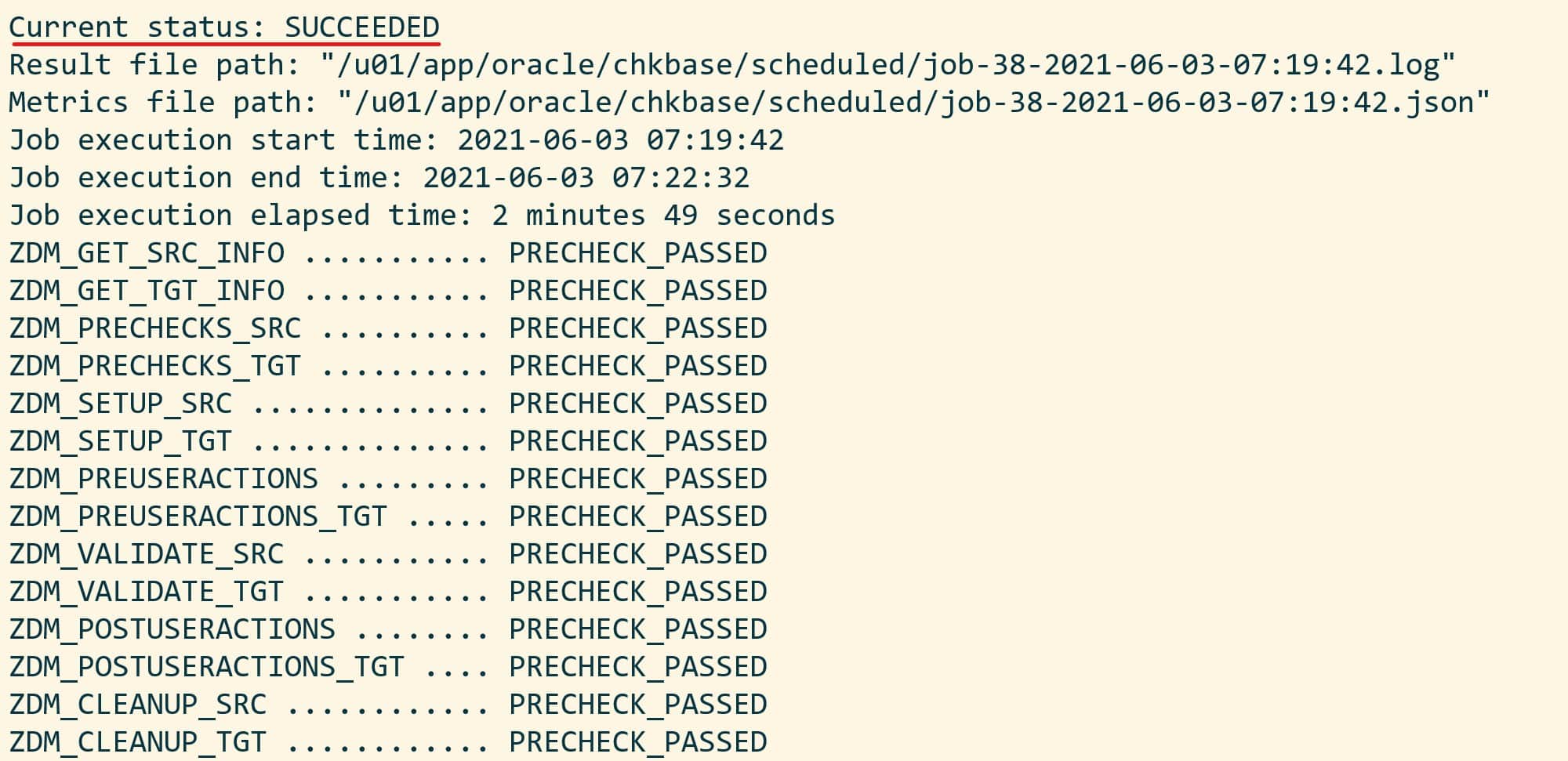
Eventually, I end up with a successful evaluation:
Start Migration
When the evaluation passes, I can start the real migration. I am re-using the same command line, but I have removed the -eval option. Instead – and this is important – I am using -pauseafter to tell ZDM to pause the migration, just before the switchover takes place. Downtime has not started yet. The database is still open for business, but ZDM will copy the data and configure Data Guard:
[zdmuser@zdmhost]$ $ZDM_HOME/bin/zdmcli migrate database \
-rsp /home/zdmuser/physical_online.rsp \
-sourcenode srchost \
-sourcedb SALES_fra3fw \
-srcauth zdmauth \
-srcarg1 user:opc \
-srcarg2 identity_file:/home/zdmuser/.ssh/srchost_key_file \
-srcarg3 sudo_location:/usr/bin/sudo \
-targetnode tgthost \
-tgtauth zdmauth \
-tgtarg1 user:opc \
-tgtarg2 identity_file:/home/zdmuser/.ssh/tgthost_key_file \
-tgtarg3 sudo_location:/usr/bin/sudo \
-targethome /u01/app/oracle/product/12.1.0.2/dbhome_1 \
-backupuser "daniel.overby.hansen@oracle.com" \
-pauseafter ZDM_CONFIGURE_DG_SRC
Again, I have to input the passwords as in eval mode. Use the job ID to monitor the progress or tail the log file. Note down the job ID. I need it later on to resume the migration.
When ZDM completes the phase ZDM_CONFIGURE_DG_SRC it will pause and wait. I can verify it with zdmcli query job:
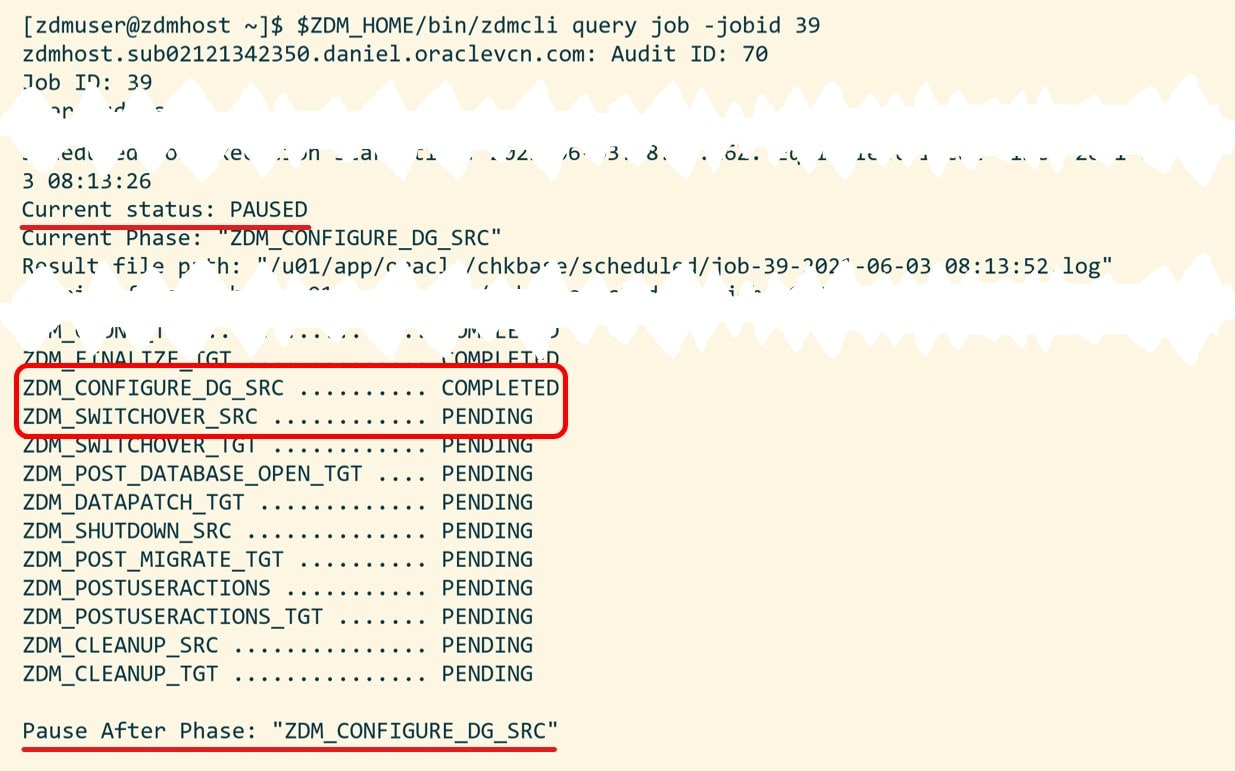
Now the standby database has been built in OCI. Redo gets transferred from my source database to the target database in OCI and is applied (see appendix D for monitoring queries). Also, this is a good time to test your new database.
Complete Migration
Now it is time to finalize the migration and switch over to the OCI target database. All I need to do, is to resume the paused ZDM job. I use the job ID that was created when I started the migration:
[zdmuser@zdmhost]$ $ZDM_HOME/bin/zdmcli resume job -jobid <job ID>
ZDM will now ensure that all redo is sent and applied before switching over to the OCI target database. Again, I use the zdmcli query job command to monitor the progress and I can tail the log file. After a short while the migration completes.

That’s it. I have now migrated into OCI!
I have a few post-migration tasks to carry out:
- Configure automatic backup
- Protect my new OCI database with a Data Guard in OCI
- Take a peek at the alert log (just be sure)
Other Blog Posts in This Series
Appendix
A – RAC Databases
If your source or target database is a RAC database, then you only need access to one of the nodes. Select the node that you want to use and use the host name and SSH keys to that host.
Also, ensure that the IP address you are using is not the floating one (VIP). In OCI that is referred to as the private IP.
B – Response File
Allow me to put some comments on the values:
| Setting |
Comment |
| DATA_TRANSFER_MEDIUM |
When migrating to a DB System in OCI OSS is the only option. It is also the default value, so I could omit the parameter. The other options are applicable for Exadata Cloud at Customer and Exadata on-prem. |
| HOST |
Getting the right URL for the HOST parameter might be a little tricky, but check the documentation. In my demo I use the Frankfurt data center, and, thus, the region is set to eu-frankfurt-1. Visit the API documentation for a list of regions. Use OCI CLI and oci os ns get to find the tenancy object storage namespace. Alternatively, in the OCI Console (the web page) open the Profile menu and click Tenancy: <your tenancy name>. The namespace string is listed under Object Storage Settings. To read more about have a look at the OCI documentation. Thanks to Bartlomiej Sowa for putting in a comment with this information – much appreciated! |
| OPC_CONTAINER |
The OCI Object Storage bucket that will be used as a staging area for the backup of the source database. I recommend using a separate bucket for each migration. It makes it a lot easier to clean up afterwards. |
| PLATFORM_TYPE |
VMDB covers Virtual Machine and Bare Metal DB Services. It is also the default value, so I could omit the parameter. |
| SHUTDOWN_SRC |
I choose to shut down the source database to ensure no one uses it unintentionally after the migration. |
| SKIP_FALLBACK |
To make my demo simple I choose not to configure fallback. Remember falling back to the source database requires a license for Advanced Security Option or setting the paramete TABLESPACE_ENCRYPTION correctly. |
| TGT_DB_UNIQUE_NAME |
The DB_UNIQUE_NAME of the target placeholder database. It must be different than that of the source database. |
C – Backup Strategy
During a migration with ZDM, you should keep your regular backup strategy. Keep doing the same backups as you did before. But avoid having ZDM backups and regular backups run at the same time. Also, if you are dealing with a RAC database be sure to put the snapshot control file on shared storage. Otherwise, you might get ORA-00245 errors during backups.
D – Monitoring
Use these queries to monitor the redo apply. On source/primary database:
SELECT
host_name, instance_name, db_unique_name, status, database_role, open_mode
FROM
v$database, v$instance;
SELECT thread#, max(sequence#) FROM v$archived_log GROUP BY thread#;
Target/standby database:
SELECT
host_name, instance_name, db_unique_name, status, database_role, open_mode
FROM
v$database, v$instance;
SELECT thread#, max(sequence#) FROM v$archived_log WHERE applied='YES' GROUP BY thread#;
--MRP process should be 'APPLYING_LOG'
SELECT process, status, sequence# FROM v$managed_standby;
SELECT * FROM v$archive_gap;
E – Troubleshooting
PRCZ-4001
If you run into this error:
PRCZ-4001 : failed to execute command "/bin/uname" using the privileged execution plugin "zdmauth" on nodes "doverbyh-zdm-tgt" within 120 seconds
PRCZ-2006 : Unable to establish SSH connection to node "doverbyh-zdm-tgt" to execute command "/bin/uname"
No more authentication methods available
Check your key files. They must be in RSA/PEM format (the private key must start with -----BEGIN RSA PRIVATE KEY-----).
ZDM_OBC_INSTALL_CREDENTIALS_INVALID
If you run into this error:
srchost: 07:08:00.000: Validating object store credentials..
srchost: <ERR_FILE><Facility>PRGO</Facility><ID>ZDM_OBC_INSTALL_CREDENTIALS_INVALID</ID></ERR_FILE>
Check your credentials to OCI. Remember when prompted for the password of your OCI account it is an auth token, not your password (even though the prompt text is misleading).
ZDM_GET_SRC_INFO
If the phase ends in PRECHECK_FAILED and there is no real clue about the error, ensure that the source database host is added to the known_hosts file on the ZDM service host.
Also, you can verify connectivity by trying to log on via SSH:
[zdmuser@zdm]$ ssh -i <specified-key-file> opc@<name-of-source-host>
ZDM_GET_TGT_INFO
If the phase ends in PRECHECK_FAILED and there is no real clue about the error, ensure that the target database host is added to the known_hosts file on the ZDM service host.
[zdmuser@zdm]$ ssh -i <specified-key-file> opc@<name-of-target-host>
ZDM_SWITCHOVER_SRC
If the migration is stuck at the phase ZDM_SWITCHOVER_SRC and you see the following in the ZDM log file:
zdmhost213: 2022-05-10T18:01:22.565Z : Executing phase ZDM_SWITCHOVER_SRC
zdmhost213: 2022-05-10T18:01:22.566Z : Switching database SALES2_fra3cx on the source node srchost to standby role ...
zdmhost213: 2022-05-10T18:01:22.566Z : checking if source database is ready for switching role...
srchost: 2022-05-10T18:01:35.340Z : Validating database SALES2_fra3cx role is PRIMARY...
srchost: 2022-05-10T18:01:35.742Z : Validating database SALES2_fra3cx is in open mode...
srchost: 2022-05-10T18:01:36.144Z : Waiting for SALES2_fra3cx to catch up, this could take a few minutes...
Then proceed to primary and standby database and investigate whether there are any log shipping or log apply problems. The root cause can be many different things, for instance conflicts when negotiating network security options.
PRGZ-3420 / ZDM_MANIFEST_TO_CLOUD
Check the ZDM log file stored on the ZDM service host in $ZDM_BASE/chkbase/scheduled. If you find this error:
zdmhost213: 2022-05-10T18:20:34.330Z : Executing phase ZDM_MANIFEST_TO_CLOUD
zdmhost213: 2022-05-10T18:20:34.331Z : registering database "SALES2_OCI" to Oracle Cloud
tgthost: 2022-05-10T18:20:50.895Z : Updating DBAAS wallet keys ...
####################################################################
PRGZ-3420 : failed to modify keystore entry "oracle.security.client.password1" in wallet "/var/opt/oracle/dbaas_acfs/sales2/db_wallet".
The proceed to the target host and find the log file from that phase. It is located in $ORACLE_BASE/zdm/zdm_<target_db_unique_name>_<zdm_job_id>/zdm/log. Do a grep:
cd /u02/app/oracle/zdm/zdm_SALES2_OCI_12/zdm/log
grep "cloud registry" zdm_manifest_to_cloud_*.log
If you find the following lines in the log file:
grep "Error: Missing cloud registry" zdm_manifest_to_cloud_*.log
zdm_manifest_to_cloud_337115.log:Error: Missing cloud registry file SALES2.ini
zdm_manifest_to_cloud_337115.log:Error: Missing cloud registry file SALES2.ini
You have most likely used the wrong case of DB_NAME on the target database. You choose that in the OCI console in the field Database name.
In this case, DB_NAME in source database is SALES2, but I had incorrectly used sales2 (lowercase) for the target database. Normally, DB_NAME is case insensitive, and it is to the database itself. But the OCI cloud tooling is not case insensitive.
Looking in /var/opt/oracle/creg on the target database, I can find a file called sales2.ini but ZDM is looking for SALES2.ini.
How do you solve this? If this is a test database, then scratch everything and start all over. But bear in mind that the switchover has already taken place, and the OCI database is now the primary database.
For a production database this is tricky. First, the database has been migrated to OCI. It works. All your data is fine on the target database. But the OCI cloud tooling does not work properly. You need to open a SR and get assistance from support.
PRGO-4086 : failed to query the "VALUE" details from the view "V$ARCHIVE_GAP" for database "target_db_name"
If the switchover fails during this query:
select count(*) from v$archive_gap
And your target database is 11.2.0.4 or 12.1.0.2, you have hit bug 18411339 (Low performance or ORA-1220 for query on V$ARCHIVE_GAP on 11.2.0.4 or later release). Apply the patch on the target database and retry the ZDM migration.
You can also open the target database before you start the switchover process (requires Active Data Guard because redo apply must be on). The above query fails only when the standby database (the target database) is mounted. It works fine on an open database.











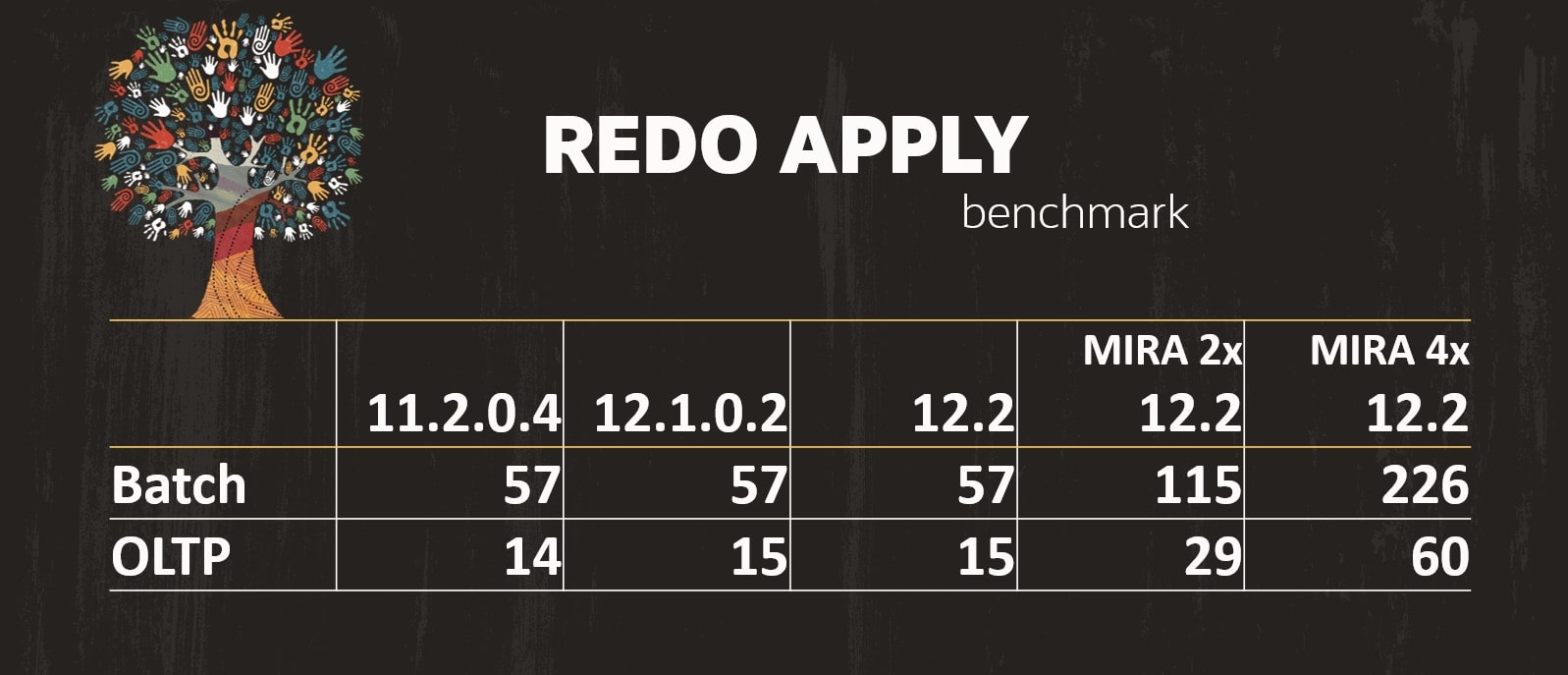 The numbers of the above graph comes from
The numbers of the above graph comes from