

First, what is Oracle Fleet Patching and Provisioning (FPP)?
Oracle Fleet Patching & Provisioning (formerly known as Oracle Rapid Home Provisioning) is the recommended solution for performing lifecycle operations (provisioning, patching & upgrades) across entire Oracle Grid Infrastructure and Oracle RAC Database fleets and the default solution used for Oracle Database Cloud services.
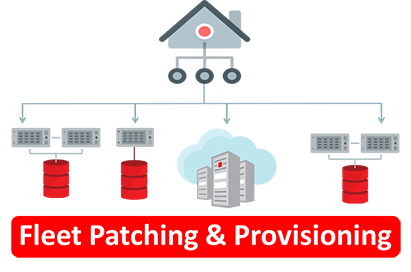
In my own words, a central server that provision, patch, and upgrade your Oracle Databases, Oracle Grid Infrastructure, and Oracle Exadata stack.
With FPP, the lifecycle operations are automated and handled centrally. The more systems you have, the greater the benefit of FPP.
If you are constantly busy trying to keep up with all the patching, or struggling to maintain your tooling, then it is time to look into FPP!
Many Good Reasons To Use Oracle Fleet Patching and Provisioning
Oracle Fleet Patching and Provisioning:
- Uses a gold image approach to provision new Oracle Database and Grid Infrastructure homes.
- Manages your software centrally. Install a new database or GI home based on a gold image centrally with one command.
- Patches your database or GI home, including running datapatch.
- Uses out-of-place patching to minimize downtime.
- Makes it easy to use Zero Downtime Oracle Grid Infrastructure Patching (ZDOGIP).
- Patches your entire Oracle Exadata stack, including the nodes, storage cells, and RoCE and Infiniband network.
- Upgrades your databases using different approaches. Of course, FPP uses AutoUpgrade underneath the hood.
- Creates new databases.
- Adds nodes to your Oracle RAC cluster.
- Detects missing bugfixes. If prior to patching database or GI home doesn’t have the expected patches, you are notified. Optionally, you can add the missing fixes to your gold image.
- Checks for configuration drift. Compares the bug fixes in a gold image to the homes deployed.
- Adheres to the MAA best practices. Provides options to control session draining, and perfectly integrates with Transparent Application Continuity. It will always use the latest HA and MAA features.
- Does it the same way every time. No more human errors.
All of the above is done centrally from the FPP server.
Imagine how much time you spend on patching your Oracle stack. Now, take into consideration that you are doing it every quarter. Now, take Monthly Recommended Patches into account. Now, take all the other tasks into account. You can really save a lot of time using Oracle Fleet Patching and Provisioning.
But …
I need to learn a new tech!
You’re right. But there are so many resources to get you started:
- Oracle Live Labs.
- Vagrant builds to spin up an FPP test environment quickly.
- Fleet Patching & Provisioning by example blog series.
- Philippe Fierens is Product Manager for FPP. If not the most helpful Product Manager at Oracle, then he is at least one of the most helpful ones. He will get you started quickly.
It Requires a License
True, but it comes included in your Oracle RAC license. If you don’t have that, you must license the Enterprise Manager Lifecycle Management pack. Check the license guide for details.
My Database Is On Windows
OK, bummer. Then you can’t use FPP. It supports Linux, Solaris, and AIX only.
What’s the Result?
Settling the score is easy. There are many more pros than cons.
I recommend using Oracle Fleet Patching and Provisioning when you manage more than a few systems. It will make your life so much easier.
I interviewed Philippe Fierens, the product manager for Oracle Fleet Patching and Provisioning, on the benefits of using FPP.
Appendix
Further Reading
- Product Page: Oracle Fleet Patching & Provisioning
- Technical Brief: Oracle Fleet Patching and Provisioning (FPP) – Introduction and Technical Overview
- Documentation: Oracle Fleet Patching and Provisioning Administrator’s Guide
- Blog post: FPP by Example
- Live Labs: Oracle Fleet Patching and Provisioning (FPP) – Quick Start
Other Blog Posts in This Series
- Introduction
- How to Patch Oracle Grid Infrastructure 19c Using In-Place OPatchAuto
- How to Patch Oracle Grid Infrastructure 19c Using Out-Of-Place OPatchAuto
- How to Patch Oracle Grid Infrastructure 19c Using Out-Of-Place SwitchGridHome
- How to Patch Oracle Grid Infrastructure 19c and Oracle Data Guard Using Standby-First
- How to Patch Oracle Grid Infrastructure 19c Using Zero Downtime Oracle Grid Infrastructure Patching
- How to Patch Oracle Restart 19c and Oracle Database Using Out-Of-Place Switch Home
- Which Method Should I Choose When Patching Oracle Grid Infrastructure 19c
- How to Avoid Interruptions When You Patch Oracle Grid Infrastructure 19c
- Patching Oracle Grid Infrastructure And Oracle Data Guard
- How to Clone Oracle Grid Infrastructure Home Using Golden Images
- How to Roll Back Oracle Grid Infrastructure 19c Using SwitchGridHome
- How to Remove an Old Oracle Grid Infrastructure 19c Home
- Use Cluster Verification Utility (cluvfy) and Avoid Surprises
- A Word about Zero Downtime Oracle Grid Infrastructure Patching
- Why You Need to Use Oracle Fleet Patching and Provisioning
- My Best Advice on Patching Oracle Grid Infrastructure
- Pro Tips

