
This blog post is outdated!
There’s a newer blog post for upgrades to Oracle AI Database 26ai.
Upgrade Oracle Database 19c CDB to 26ai with Data Guard – MAA Method
Let me show you how to upgrade your database to Oracle Database 19c when it is protected by Data Guard. I will use AutoUpgrade and follow the MAA method.
This is my demo environment:
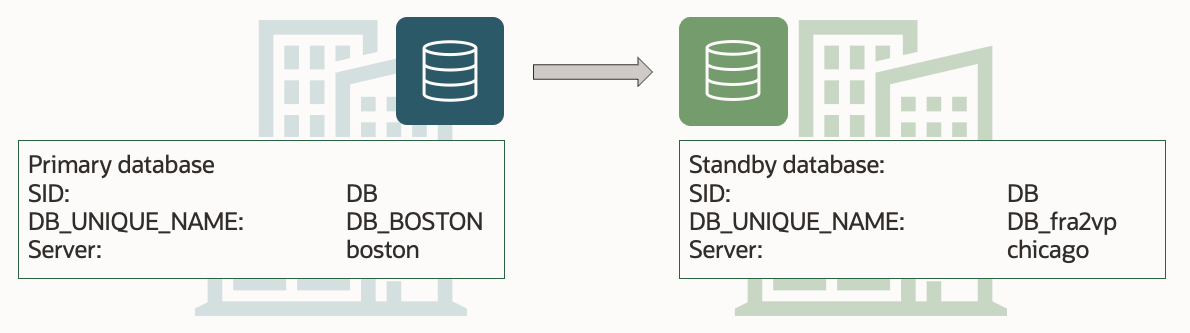
- Grid Infrastructure is managing the database.
- Data Guard is configured using Data Guard broker.
Overall, the process looks like this:

This procedure starts right before I start AutoUpgrade in DEPLOY mode. Downtime has begun, and no users are connected to the database.
Before Upgrade
I always use the latest version of AutoUpgrade. Download it and put it into $ORACLE_HOME/rdbms/admin.
A newer version of AutoUpgrade can also upgrade to older database releases, so don’t worry if the AutoUpgrade version doesn’t match the Oracle Database release that you are upgrading to.
Disable Fast-Start Failover (FSFO)
Fast-Start Failover must be disabled during upgrade. I connect to Data Guard CLI (dgmgrl) and disable it:
DGMGRL> disable fast_start failover;
Restore Point
I need to protect the standby database against errors during the upgrade. I create a guaranteed restore point on the standby database:
STANDBY SQL> alter database recover managed standby database cancel;
STANDBY SQL> create restore point stdby_before_upg guarantee flashback database;
STANDBY SQL> alter database recover managed standby database disconnect from session;
Set Parameters
If I plan on making changes to the database initialization parameters as part of the upgrade of the primary database, I probably also want to make the same changes on the standby database.
I can make changes to database initialization parameters using these AutoUpgrade config file parameters:
remove_underscore_parametersadd_after_upgrade_pfileadd_during_upgrade_pfiledel_after_upgrade_pfiledel_during_upgrade_pfile
I can also review the Preupgrade Summary Report for suggested changes to the database initialization parameters.
Save the changes to the SPFile only:
STANDBY SQL> alter system set ... scope=spfile;
Restart Standby Database In New Oracle Home
The standby database must be started in the new Oracle Home; the Oracle Home I upgrade to.
-
First, I stop the standby database:
[oracle@standby]$ srvctl stop database -d $ORACLE_UNQNAME -
Ideally, I have stored these files outside the Oracle Home; like ASM. In that case, I don’t need to do anything:
- SPFile
- Password file
- Data Guard broker config files
- Network files (sqlnet.ora, tnsnames.ora etc.)
If I stored the files inside the Oracle Home, I must move them to the new Oracle Home (see appendix).
-
Next, I restart the database in the new Oracle Home. I must restart in mount mode:
[oracle@standby]$ #Set environment to new Oracle Home [oracle@standby]$ export ORACLE_HOME=/u01/app/oracle/product/19.0.0.0/dbhome_1 [oracle@standby]$ export PATH=$ORACLE_HOME/bin:$PATH [oracle@standby]$ srvctl upgrade database -d $ORACLE_UNQNAME -oraclehome $ORACLE_HOME [oracle@standby]$ srvctl start database -d $ORACLE_UNQNAME -o mountI don’t need to explicitly start redo apply. My Data Guard broker configuration has APPLY-ON for the standby database. Since the broker is still enabled, it will ensure that redo apply is started.
-
Finally, be sure also to change my profiles and /etc/oratab (see appendix).
Upgrade
Upgrade the primary database by starting AutoUpgrade in DEPLOY mode:
[oracle@primary]$ java -jar autoupgrade.jar -config DB.cfg -mode deploy
As the upgrade progresses, it makes a lot of changes to the database data dictionary. Those changes are written to redo, which the standby database will apply. Thus, the upgrade happens implicitly on the standby database via the redo.
After Upgrade
Check Standby Database
Ensure that the standby database has caught up and applied all the redo generated during the upgrade.
I use Data Guard CLI (dgmgrl) to check it. First, the configuration:
DGMGRL> show configuration
Configuration - DB_BOSTON_DB_fra2vp
Protection Mode: MaxPerformance
Members:
DB_BOSTON - Primary database
DB_fra2vp - Physical standby database
Fast-Start Failover: Disabled
Configuration Status:
SUCCESS (status updated 28 seconds ago)
Status must be SUCCESS.
Next, I check each of the databases:
DGMGRL> show database "DB_BOSTON"
DGMGRL> show database "DB_fra2vp"
Both databases should have status SUCCESS, and the standby database must report no apply lag.

If Data Guard broker reports an erroror the standby database is not applying logs, I can try to enable the configuration again:
DGMGRL> enable configuration;
Validate Data Guard
I validate the setup and ensure both databases are ready for a switchover. The database will not allow a switchover if there are any problems in the Data Guard setup. It is a good way of checking things are fine:
DGMGRL> validate database "DB_BOSTON"
DGMGRL> validate database "DB_fra2vp"

Optionally, I perform a switchover as well:
DGMGRL> switchover to "DB_fra2vp"
Re-enable Fast-Start Failover
I can now re-enable FSFO:
DGMGRL> enable fast_start failover;
Active Data Guard
If the database is licensed to use Active Data Guard, I can now open the standby database in READ ONLY mode.
Remove Restore Points
After the upgrade, I should perform the necessary tests to validate the new database release. Only when I am convinced to go live on the new release, should I remove the restore points on both databases.
Miscellaneous
Check the database registration in listener.ora. I must update the Oracle Home information if there is a static configuration.
What If
-
What if your Oracle Database is not managed by Grid Infrastructure? You can still use the above procedure, but you must change the commands accordingly.
-
What if you don’t use Data Guard broker? Manually configured Data Guard environments are fully supported by AutoUpgrade, but you must change some commands accordingly.
Conclusion
It is not that complicated to upgrade your database, even if it is part of a Data Guard setup. Using AutoUpgrade is fully supported and highly recommended. A little extra legwork is needed to take care of the standby database. But the good thing is that your Data Guard setup is maintained throughout the process.
Here is a cool demo of the entire process:
Other Blog Posts in This Series
- Introduction
- How To Upgrade Data Guard – MAA Method
- How To Upgrade Data Guard – Standby Offline Method
- Changing COMPATIBLE Parameter
- Downtime
- Restore Points
- Flashback
- Downgrade
Appendix
Broker Config Files
Here is a query to determine the location of the Data Guard broker config files. In this example, the files are stored outside the Oracle Home; in ASM:
SQL> select name, value from v$parameter where name like 'dg_broker_config_file%';
NAME VALUES
---------------------- --------------------------------
dg_broker_config_file1 +DATA/DB_FRA2PR/dr1db_fra2pr.dat
dg_broker_config_file2 +DATA/DB_FRA2PR/dr2db_fra2pr.dat
Database Files
Here is a command to see where the SPFile and password file are located. In this example, the SPFile is stored outside the Oracle Home. However, the password file is in the default location inside the Oracle Home. The latter must be moved when you restart a database in the new Oracle Home:
[oracle@standby]$ srvctl config database -d $ORACLE_UNQNAME | grep -E "Spfile|Password"
Spfile: +DATA/<DB_UNIQUE_NAME>/PARAMETERFILE/spfileDB.ora
Password file:
Updating /etc/oratab
Here is a little snippit to update /etc/oratab to match the new release Oracle Home. Since I am using Grid Infrastructure to manage my database, I don’t set the database to start automatically:
export NEW_ORACLE_HOME=/u01/app/oracle/product/19.0.0.0/dbhome_1
export ORACLE_SID=DB
#Backup file
cp /etc/oratab /tmp/oratab
#Use sed to remove the line that starts with ORACLE_SID
sed '/^'"$ORACLE_SID"':/d' /tmp/oratab > /etc/oratab
#Add new entry
echo "$ORACLE_SID:$NEW_ORACLE_HOME:N" >> /etc/oratab
Updating .bashrc
Here is a little snippit to update .bashrc replacing the old Oracle Home with the new Oracle Home:
export OLD_ORACLE_HOME=/u01/app/oracle/product/12.2.0.1/dbhome_1
export NEW_ORACLE_HOME=/u01/app/oracle/product/19.0.0.0/dbhome_1
cp ~/.bashrc ~/.bashrc-backup
sed 's|'"$OLD_ORACLE_HOME"'|'"$NEW_ORACLE_HOME"'|g' ~/.bashrc-backup > ~/.bashrc
Config File
For your reference, this is the config file I used. It contains only the required information. All other parameters have a default value:
upg1.sid=DB
upg1.source_home=/u01/app/oracle/product/12.2.0.1/dbhome_1
upg1.target_home=/u01/app/oracle/product/19.0.0.0/dbhome_1
Synchronize Standby Database
When I run AutoUpgrade in ANALYZE mode and check the preupgrade summary report, I find this information message:
Synchronize your standby databases before database upgrade.
The standby database is not currently synchronized with its associated primary database.
To keep data in the source primary database synchronized with its associated standby databases, all standby databases must be synchronized before database upgrade. See My Oracle Support Note 2064281.1 for details.
Don’t worry about it. It tells me to ensure that all redo gets applied
What does it say? Basically, it says that all redo generated on the primary database before the downtime window started, should be sent to and applied on the standby database. This way, my standby database is ready to replace your primary database at any time, if something goes really wrong. Strictly speaking it is not necessary to ensure that, but it is strongly recommended.
Further Reading
- AutoUpgrade and Oracle Data Guard, Oracle Database 21c Upgrade Guide
- Patching, Upgrading, and Downgrading Databases in an Oracle Data Guard Configuration, Oracle Database 19c Data Guard Concepts and Administration
- Oracle Data Guard Broker Upgrading and Downgrading, Oracle Database 19c Data Guard Broker
- Oracle Data Guard Command-Line Interface (DGMGRL) Reference, Oracle Database 19c Data Guard Broker
- 19c Grid Infrastructure and Database Upgrade steps for Exadata Database Machine running on Oracle Linux (Doc ID 2542082.1)
- When you upgrade, disable the Data Guard Broker, Mike Dietrich blog post








 The numbers of the above graph comes from
The numbers of the above graph comes from 